Our Motivation
In this project we want to develop a machine learning model to give game recommendation based on user's rating of other games. In mordern e-commerce, recommendation system are very common, but we haven't seen a lot of good one for video games. Our goal is to give players more accurate recommendations so that they won't waste their money and time.
Our task is to provide a recommendation list of games to players base on player’s reviews on games he/she has played in the past, along with other features like game category and game level. We will apply a few machine learning algorithm to the dataset collected from several game website to achieve better and more accurate recommendation. With the recommendation list, user could not only save lots of money on other games they might not interest in, but also saving a great amount of time to search for games fit for them. That’s why we consider this is a pretty important task for us to explore.
Our Solution
We pulled data from Metacritic including user's rating to the game, game titles, developers, platforms and their genres. Metacritic is a web site that aggregats reviews of media product including games. One game can belong to mutiple genres or Platforms. To do the recommendation we train the model and give a user we classify a game to recommend or not recommend. We use sci-kit learn package to implement our algorithm. Scikit-learn is a machine learning library in Python which provide us most of the fundamental algorithms thus allow us develop more easily. Our dataset features 9090 real user data from Metacritic.
Our Dataset
We get the dataset from metacritic.com by crawling and scraping data by Scrapy and the dataset is from 2012 to now. The total number of our data is about 37000 user reviews and 1397 game data, and the data have features of game title, game critic score, game user score, game platform, game genre, publisher and developer of the game, game rating, user name, user score on single game, user’s average review score. The attributes of each game is title, rating, developer, genre and metascore.
We use title, rating, developer, publisher, metascore and genre for training, use user_score as the result for us to predict. Half of the data was used for training and 10-fold validation, and the other half for testing. We implemented first recommendation system by KNN algorithm with python library ‘sklearn.neighbors.KNeighborsClassifier’. After converting attributes such as title, rating, developer, publisher and genre into numerical attribute, we apply the classifier into our model and run a 10-fold validation. If we predict whether the user_score is greater or less than 5, the accuracy will be 85%. And to predict which range the user_score is in among the 5 range: (0, 2], (2, 4], (4, 6], (6, 8], (8, 10], the accuracy will be 61%.
Our Training&testing
We trained multiple algorithms at the same time and use 10-fold cross-validation to assure the models' generalizablity. We also use different parameters to find the optimal model. We convert the 0-10 rating to 0-5 points.
Our Result
We trained KNN, multi layer perceptron, decision tree, random forest, ada boost, Naive Bayes Classifier, Quadratic discrminant analysis and Support Vector Classification. The Decision tree classifier performed the best with an accuracy of 57.9%. By using Ada boosting we improved our results to achieve 60% accuracy. Due to the limitaion of the hardware we were not able to get more data so the results are not perfect. Also we noticed that some algorithms are doing extremely bad on this dataset, like the naive bayes algorithm. If we could have more user record and sense more connections between people, we can find more internal relations and help improve thr recommrndation.

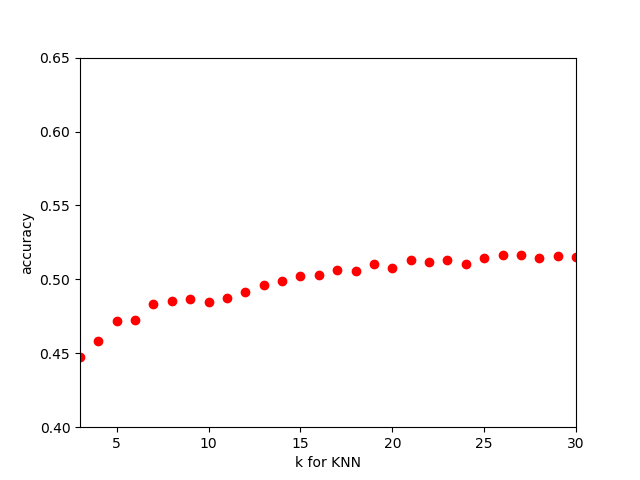
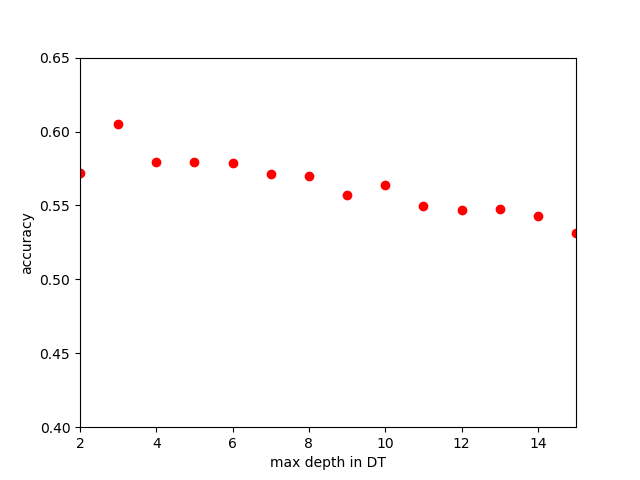
We find a peak point while the max depth in decision tree is 3.